- Português
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Como Funcionam os Dispositivos IoT: Arquitetura, Componentes e Fatores de Desempenho
Catálogo
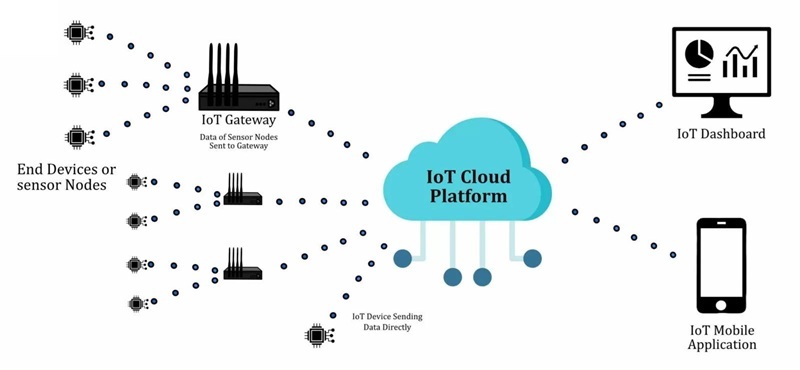
Como um Dispositivo IoT Funciona
Um produto IoT é mais fácil de raciocinar quando é tratado como um loop fechado e mensurável: observa o mundo físico, converte o que observou em dados que a eletrônica pode processar, move esses dados para um local onde podem ser interpretados e, em seguida, desencadeia uma resposta. Muitas equipas começam por buscar a “conectividade”, e isso é compreensível, as demonstrações parecem ótimas quando o painel é atualizado em tempo real, mas no campo, o dispositivo é avaliado pela maneira como se comporta no dia 3, dia 30 e dia 300.
O loop tem que sobreviver às restrições do dia a dia que tendem a aparecer nos piores momentos: energia limitada, latência imprevisível, interferência, limites de custo e expectativas de segurança em evolução. Quando o loop é projetado com essas restrições em mente, as camadas de rede e nuvem parecem uma extensão limpa do produto, em vez de uma fonte de surpresas e casos extremos frágeis.
Detectar: Transformando um Sinal Físico em um Elétrico
Na borda, um sensor converte uma variável do mundo real em uma representação elétrica que o dispositivo pode medir. A variável pode ser ambiental, mecânica ou elétrica, e o trabalho do sensor é criar um sinal que permaneça interpretável em meio a oscilações de temperatura, vibração e variabilidade na instalação.
Variáveis do mundo real comumente medidas:
• Temperatura
• Vibração
• Pressão
• Luz
• Movimento
• Corrente
• Concentração de gás
A saída do sensor geralmente cai em um de dois grupos, e a escolha afeta tudo a montante (design de front-end, amostragem e tolerância a ruído).
Tipos comuns de saída de sensor:
• Analógica: uma tensão ou corrente que varia continuamente
• Digital: leituras em pacotes através de I²C/SPI/UART
Fora das condições de laboratório, a precisão da medição depende de mais do que o sensor em si. Fatores de instalação, como colocação, força de montagem, fluxo de ar, fontes de calor próximas, roteamento de cabos e acoplamento mecânico, podem afetar significativamente os resultados.
Erros de medição são frequentemente causados por problemas de instalação em vez de falhas do sensor. Superfícies de montagem flexíveis ou estruturas ressonantes podem distorcer dados e criar leituras enganosas. Tratar o projeto de montagem e mecânico como parte do sistema de medição ajuda a reduzir o tempo de resolução de problemas e melhora a confiabilidade das medições.
Condicionar: Frente Analógica (AFE) e Higiene do Sinal
Muitos dispositivos encaminham saídas brutas de sensores através de uma frente analógica (AFE) antes de digitalizar. Esta etapa molda silenciosamente se o resto do sistema está trabalhando com um sinal estável e confiável ou com algo que se comporta apenas em condições controladas.
Funções típicas da AFE:
• Polarização e geração de referência para manter sinais dentro da faixa de entrada válida do ADC
• Amplificação (amplificadores de instrumentação, estágios de ganho) para tornar sinais pequenos mensuráveis
• Filtragem (filtro passa-baixas, filtragem anti-aliasing) para reduzir ruídos e limitar conteúdos de alta frequência enganadores
• Proteção (estruturas ESD, proteção contra surtos, garras de entrada) para sobreviver a erros de fiação e manuseio
Os ambientes de operação reais muitas vezes introduzem fontes de ruído como motores, cabos longos, reguladores de comutação e rádios próximos. Esses efeitos podem criar erros de medição que podem parecer aleatórios até que a fonte seja identificada.
Um bom aterramento, isolamento adequado e filtragem anti-aliasing básica muitas vezes melhoram a qualidade do sinal de forma mais eficaz do que depender apenas de filtragem de software complexa. Abordar o ruído na fonte geralmente produz medições e desempenho do sistema mais confiáveis.
Converter: Amostragem ADC com Compromissos Intencionais
Quando o sinal é analógico, um ADC converte-o em amostras digitais. A conversão em si é direta; o que tende a exigir experiência é escolher parâmetros de amostragem que se comportem bem sob os limites reais da bateria e da rede.
Duas escolhas de amostragem que moldam o comportamento a montante:
• Taxa de amostragem: rápida o suficiente para capturar o fenômeno, mas não tão rápida que consuma energia e produza dados desnecessários
• Resolução: fina o suficiente para detectar mudanças significativas sem transformar ruído e deriva em precisão falsa
A amostragem funciona melhor quando é tratada como uma decisão a nível de sistema em vez de uma especificação isolada. A superamostragem pode forçar silenciosamente mais atividade de rádio (e o tempo de rádio é frequentemente o que drena a bateria primeiro). A subamostragem pode perder eventos curtos, operacionalmente significativos, picos de pressão, impactos, breves pausas, que os usuários se lembram porque foram o momento em que algo deu errado.
Calcular: Processamento do Microcontrolador, Sincronização e Lógica de Borda
Um microcontrolador (MCU) normalmente lê dados de sensores em um cronograma disciplinado usando temporizadores, interrupções e DMA para que o temporizador do dispositivo permaneça consistente mesmo quando o firmware cresce. Um tempo consistente é um daqueles detalhes que parecem chatos até o dia em que você está depurando um problema em campo e percebe que o “sinal” era na verdade jitter de agendamento.
Tarefas comuns de processamento do lado do MCU:
• Filtragem digital (média móvel, mediana, IIR) para reduzir jitter e valores discrepantes
• Calibração e compensação (correção de deslocamento, compensação de temperatura, linearização)
• Avaliação de regras (limiares, histerese, debounce) para evitar alternâncias instáveis
• Análises de borda leves (extração de características, pontuação de anomalias, compressão) para reduzir largura de banda e computação em nuvem
Uma abordagem de design útil é separar os dados de medição da lógica de decisão. As leituras do sensor podem flutuar devido a condições físicas normais, enquanto um comportamento do sistema estável pode ser mantido por meio de histerese, janelas de tempo e controle de máquina de estados. Essa separação ajuda a reduzir alarmes falsos, melhora a estabilidade do sistema e previne indicações incorretas de falhas quando ocorrem variações temporárias de medição.
Nem toda decisão se beneficia de esperar pela nuvem. Algumas ações são sensíveis ao tempo ou orientadas à prevenção de danos, e empurrá-las para fora do dispositivo tende a criar modos de falha desconfortáveis quando a rede está lenta ou ausente.
Exemplos frequentemente tratados localmente:
• Corte de sobrecorrente; proteção contra superaquecimento; detecção de parada do motor
A nuvem tende a brilhar quando a tarefa se beneficia de um contexto mais amplo ou horizontes de tempo mais longos.
Categorias de decisão do lado da nuvem:
• Análise de tendência de longo prazo e manutenção preditiva
• Correlação entre dispositivos
• Atualizações de modelo e mudanças de políticas em toda a frota
Uma regra prática que as equipes costumam convergir é simples: se um comando atrasado puder plausivelmente causar danos, o dispositivo deve se proteger primeiro e relatar depois. Essa abordagem geralmente parece conservadora de uma maneira boa, especialmente quando você é quem está de plantão durante uma interrupção da rede.
Comunicar: Links Radiantes/Com Fios e Protocolos de Aplicação
A camada de comunicação move telemetria para um telefone, gateway ou ponto final na nuvem. Selecionar uma tecnologia de link é menos sobre o que está na moda e mais sobre o que se adapta ao ambiente físico, ao modelo de implantação e ao orçamento de energia.
Opções comuns de conectividade:
• Wi-Fi; BLE; Zigbee/Thread; celular (LTE-M/NB-IoT); Ethernet
Acima da camada de link, os dispositivos usam protocolos de aplicação para estruturar e entregar mensagens. O protocolo certo tende a depender de se o produto precisa de telemetria em streaming, fluxos de configuração ou compatibilidade com a infraestrutura empresarial existente.
Protocolos de aplicação comuns:
• MQTT
• HTTP
Implementações reais raramente oferecem conectividade estável. Pontos de acesso reiniciam, gateways desaparecem, a cobertura celular muda e a interferência vai e vem. Os dispositivos parecem muito mais confiáveis quando podem armazenar dados em buffer, tentar novamente com moderação (não de uma forma que DDoS o rede) e manter um comportamento claro do último estado conhecido para que o sistema permaneça compreensível quando os links são imperfeitos.
A telemetria é tipicamente protegida com TLS para confidencialidade e integridade. Em muitos produtos, a primeira vitória de segurança é simplesmente ativar a criptografia em todos os lugares, mas a segurança durável vai além, tornando a identidade e as atualizações gerenciáveis ao longo de toda a vida do dispositivo.
Blocos de construção de segurança comuns:
• Identidades de dispositivo únicas e autenticação baseada em certificado
• Armazenamento seguro de chaves (elementos seguros ou zonas de confiança de MCU)
• Firmware assinado e inicialização segura para reduzir a chance de execução de código não autorizado
Existe um padrão que equipes experientes reconhecem (frequentemente depois de aprendê-lo da maneira difícil): o trabalho de segurança é muito menos doloroso quando identidade, gerenciamento de chaves e caminhos de atualização são projetados desde o início. Quando essas fundações são planejadas desde o começo, o dispositivo tende a permanecer utilizável por anos, não apenas até a primeira grande atualização de campo.
Nuvem e Dados
Na nuvem (ou em uma plataforma local), os dados são armazenados, muitas vezes em sistemas de séries temporais, e depois agregados e analisados. A nuvem é onde a telemetria bruta pode ser transformada em saídas nas quais alguém realmente agirá, seja esse alguém um usuário, um operador ou um motor de política automatizada.
Saídas comuns da nuvem:
• Alertas (violações de limite, detecção de falhas)
• Previsões (vida útil restante, detecção de desvio)
• Painéis (KPIs, tendências, saúde da frota/dispositivo)
• Comandos de controle (pontos de definição, agendas, ações de habilitar/desabilitar)
O valor da nuvem é mais fácil de capturar quando as equipes decidem antecipadamente quais decisões os dados devem apoiar. Sem essa disciplina, a telemetria tende a se tornar um ruído de fundo caro, coletado de forma confiável, armazenado religiosamente e, em seguida, raramente utilizado com confiança.
Acionar: Executando Comandos de Forma Segura e Repetível
Comandos enviados de volta ao dispositivo acionam atuadores, e esta parte do ciclo é onde a realidade do hardware se torna barulhenta. A ativação requer circuitos de driver correspondentes à carga e se beneficia de barreiras que tornam as falhas previsíveis em vez de caóticas.
Atuadores comuns:
• Motores
• Válvulas
• Relés
• Aquecedores
• LEDs
• Alto-falantes
Elementos de driver e proteção comuns:
• MOSFETs; relés; pontes H; triacs (dependendo das características de carga)
• Diodos de flyback e snubbers (para cargas indutivas)
• Sensores de corrente e proteções térmicas
• Verificação de estado quando disponível (interruptores de limite, feedback de posição, assinaturas elétricas)
Uma mentalidade de confiabilidade que tende a compensar é assumir que a ativação é onde o risco se concentra. Sensores frequentemente falham silenciosamente; atuadores podem falhar de maneiras que os usuários notam imediatamente. Salvaguardas simples, timeouts, intertravamentos e verificações de sanidade frequentemente previnem problemas em cascata e fazem o sistema parecer mais confiável durante os inevitáveis casos extremos estranhos.
O Ciclo se Repete
Esse sentido; ciclo de computar, comunicar, acionar se repete continuamente. Localmente, pode funcionar em milissegundos; uma viagem de ida e volta à nuvem pode levar segundos, dependendo da carga da rede e do backend. Bons produtos tratam tempo e energia como entradas de design que moldam todas as outras decisões, em vez de como reflexões tardias a serem otimizadas no final.
Estratégias comuns em nível de sistema:
• Use processamento na borda para reduzir transmissões desnecessárias
• Agrupe e comprima telemetria quando a tolerância à latência permitir
• Durma agressivamente e acorde previsivelmente em dispositivos alimentados por bateria
• Mantenha "comportamento minimamente viável" mesmo quando a nuvem não pode ser alcançada
Um dispositivo IoT durável não é definido por nenhum componente único. É definido por quão calmamente todo o ciclo se comporta quando a realidade diverge do plano: sinais barulhentos, redes intermitentes, hardware envelhecido e comportamento do usuário imprevisível. Projetar com essas condições em mente é frequentemente a diferença entre uma demonstração que funciona uma vez e um produto que mantém sua compostura ano após ano.
Componentes Eletrônicos no Desempenho do Dispositivo IoT
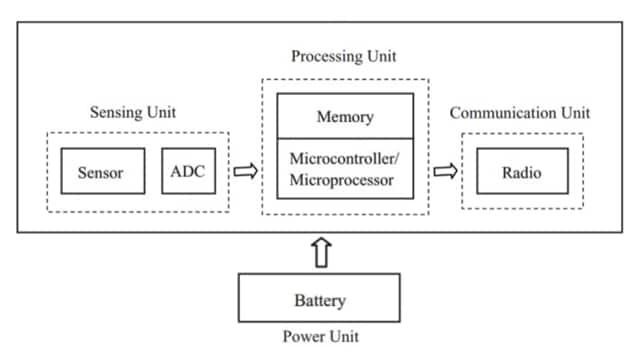
O hardware IoT tende a parecer confiável apenas quando as entradas do sensor, computação, armazenamento, fornecimento de energia e conectividade são moldadas como um único caminho contínuo de sinal e energia.
A leitura de um sensor raramente permanece significativa se a tensão de referência muda, se o clock apresenta flutuações, ou se o caminho de dados ocasionalmente perde bytes sob carga. Um link de rádio raramente permanece utilizável se a fonte cair durante os picos de transmissão, se o oscilador for ruidoso, ou se o manuseio de credenciais for inconsistente entre reinicializações.
Muitas equipas aprendem que a fiabilidade muitas vezes melhora mais ao apertar os limites entre blocos do que ao adicionar outra funcionalidade: linhas previsíveis, tempos limitados, acoplamento de ruído controlado e comportamento de falha que é compreensível quando algo se quebra.
O objetivo do design não é "peças perfeitas", mas interfaces que se comportem da mesma forma em um banco de desenvolvedor, em implantações piloto, e meses depois no campo.
Sensor
Os sensores convertem condições do mundo real em sinais elétricos, mas o comportamento productivo dia a dia é moldado por detalhes que podem parecer pequenos até que os dados de campo os façam sentir-se desconfortavelmente grandes.
Ruído, deriva, montagem, fluxo de ar, condensação e roteamento de cabos têm uma maneira de transformar um gráfico limpo em distribuições bagunçadas que o firmware deve suportar.
O alcance e a resolução precisam se encaixar na decisão que está sendo tomada, não em uma especificação de destaque. Configurações excessivamente sensíveis muitas vezes amplificam ruído e deriva, o que tende a aumentar falsos positivos e aumenta silenciosamente o tempo de computação e o tempo de transmissão de rádio. Um alcance o mais apertado possível pode parecer defensável durante as revisões de design, no entanto, o comportamento em campo muitas vezes favorece um alcance ligeiramente mais amplo que produz medições mais constantes e interpretáveis. Se um modelo ou limite a montante vai suavizar os dados de qualquer maneira, empurrar a sensibilidade bruta muito longe pode parecer satisfatório no início e então frustrante quando os tickets de suporte chegam.
A deriva, envelhecimento e exposição determinam se as medições permanecem credíveis após meses ou anos.
A calibração geralmente funciona melhor quando tratada como uma rotina de ciclo de vida em vez de um único ritual de fábrica que todos esperam que funcione para sempre.
• Calibração de fábrica com coeficientes armazenados.
• Gatilhos de recalibração em campo (programados, baseados em eventos ou assistidos por técnicos).
• Rotinas de auto-verificação que sinalizam outliers, recortes e saturação.
Equipas que visam produtos reparáveis muitas vezes reservam uma quantidade modesta de flash e computação para metadados de calibração, rastreabilidade e verificações de sanidade, porque é mais barato do que explicar leituras inconsistentes após a implantação.
A seleção da taxa de amostragem geralmente se torna uma negociação entre física, bateria e utilidade dos dados. Amostrar muito lentamente arrisca aliasing e eventos perdidos, o que pode ser difícil de diagnosticar porque os dados ainda parecem plausíveis. Amostrando muito rápido aumenta o consumo de energia e o volume de dados, e pode criar a ilusão de melhor percepção sem melhorar materialmente as decisões.
Um padrão que se mantém bem é capturar o fenômeno com margem suficiente, filtrando cedo (analógico quando realmente ajuda, digital quando é suficiente), e reduzindo a amostragem para relatórios.
Isso muitas vezes produz melhores resultados de bateria do que amostrar agressivamente e esperar que a análise em nuvem compense mais tarde.
Se um ADC externo é justificado geralmente depende de resolução, impedância de entrada, estabilidade de referência e tolerância a ruído. ADCs integrados em MCU muitas vezes têm um bom desempenho para sensoriamento de média resolução, enquanto sinais de precisão tendem a punir escolhas de layout e referência casuais.
• Seleção de referência de baixo ruído e roteamento de referência.
• Estratégia de aterramento, trilhos de proteção e controle de caminho de retorno.
• Blindagem e roteamento intencional de cabos perto de conectores.
• Proteção ESD colocada onde realmente intercepta o transiente.
Pequenas mudanças na PCB podem reduzir de forma mensurável o jitter e melhorar a repetibilidade, especialmente para fontes de alta impedância ou sinais analógicos de baixo nível onde "quase bom" se torna visivelmente instável nos dados de produção.
Microcontrolador (MCU)
O MCU atua como o centro operacional: lê sensores via GPIO, I²C, SPI e UART; condiciona sinais; executa inferências quando aplicável; gerencia modos de energia; e controla saídas.
Quando o comportamento do MCU é previsível, todo o dispositivo parece calmo; quando não é, as falhas tendem a parecer aleatórias, mesmo quando a causa é determinística.
Firmware estável geralmente vem de máquinas de estado explícitas e temporizações que têm limites claros. Designs orientados a eventos usando interrupções, DMA e temporizadores geralmente superam loops de polling em reatividade e energia, especialmente em dispositivos que dormem com frequência.
Quando as equipas descrevem travamentos aleatórios, o culpado é frequentemente um dos poucos infratores recorrentes: trabalho ilimitado dentro de uma interrupção, deadlock de barramento compartilhado, inversão de prioridade, ou fragmentação de memória que nunca foi estressada sob longos períodos de operação.
O planejamento de RAM e flash funciona melhor quando inclui o que acontece após a primeira demonstração ter sucesso.
• Buffers de rede e overhead de TLS (incluindo comportamento de handshake em pior cenário).
• Registos, métricas e dumps de falhas que os engenheiros vão implorar mais tarde.
• Espaço de staging OTA, mais metadados para verificações de integridade.
• Crescimento de funcionalidades que chega de forma previsível após o feedback do piloto.
A memória subdimensionada muitas vezes permanece silenciosa no início e depois se torna dolorosa mais tarde, bem na hora em que os diagnósticos e a segurança da atualização se tornam as principais ferramentas para controlar o risco de campo.
Dispositivos esperados para serem confiáveis geralmente se beneficiam de inicialização segura, armazenamento protegido de chaves, aceleração de criptografia por hardware e um gerador de números verdadeiramente aleatórios. Com base na experiência de implantação, melhorias de segurança tendem a ser desconfortáveis porque colidem com as restrições de hardware enviadas e credenciais de longa duração.
Selecionar um MCU (ou adicionar um elemento seguro) que suporte identidade forte e inicialização medida geralmente reduz a quantidade de software inteligente necessária para compensar raízes de confiança fracas.
O acesso para SWD/JTAG e testabilidade prática geralmente decidem se a manufatura inicial é controlada ou caótica.
• Planejamento de acesso SWD/JTAG e estratégia de bloqueio para produção.
• Pads de teste e layout amigável para sondas para fixadores de alto volume.
• Pontos de sensoriamento da linha de energia e nós mensuráveis para triagem rápida.
Uma pequena quantidade de infraestrutura de teste pode economizar semanas de adivinhações desconfortáveis quando o primeiro grande lote expõe casos extremos que nunca apareceram em protótipos construídos à mão.
Módulos de Comunicação
O módulo de comunicação molda mais do que o orçamento de link: ele influencia o provisionamento, o comportamento de atualização, os fluxos de suporte e um número surpreendente de modos de falha.
Em dispositivos alimentados por bateria, o comportamento do rádio muitas vezes domina o consumo de energia, então as decisões de conectividade tendem a se tornar decisões sobre a vida útil da bateria disfarçadas.
A seleção geralmente equilibra alcance, latência, throughput, topologia e orçamento de energia, com um olhar franco sobre o atrito operacional.
• BLE para curto alcance, baixa energia e comissionamento de smartphone.
• Wi‑Fi para maior throughput com corrente de pico mais alta e demandas de integridade de energia mais rigorosas.
• Thread/Zigbee para redes mesh e implantações de baixa potência doméstica/industrial.
• LoRaWAN para longo alcance, baixas taxas de dados e disciplina rigorosa de carga.
• LTE‑M/NB‑IoT para cobertura de larga escala com restrições de operadora e provisionamento mais complexo.
As equipes frequentemente sentem alívio uma vez que admitem que a “escolha do rádio” é inseparável da estratégia de reencaminhamento de firmware, manuseio de corrente de pico e da paciência do usuário durante a configuração.
Um módulo forte ainda pode decepcionar se a antena estiver mal posicionada, desajustada pela embalagem ou exposta a retornos de terra ruidosos.
• Zonas de exclusão para antenas e roteamento de impedância controlada.
• Efeitos da embalagem e testes de interação com o usuário.
• Verificações de emissões radiadas e sondagem de susceptibilidade.
Quando a margem de link é estreita, as tentativas de firmware podem mascarar o sintoma por um tempo, mas o custo da bateria se acumula de forma que as equipes de operações notam muito antes que os engenheiros o vejam em um laboratório.
O design de conectividade precisa sobreviver a fluxos de trabalho reais em vez de demonstrações ideais.
• Provisionamento que tolera falhas parciais e erros comuns dos usuários.
• Lógica de retrocesso e reattempt que evita espirais de drenagem de bateria autoinfligidas.
• Comportamento de roaming mais gerenciamento do ciclo de vida de SIM/eSIM para dispositivos celulares.
• OTA com autenticação, rollback e agendamento consciente da largura de banda.
As funções OTA funcionam menos como uma funcionalidade chamativa e mais como um canal de manutenção a longo prazo; quando são tratadas de forma casual, os dispositivos tendem a se tornar caros de suportar, mesmo que o primeiro lançamento pareça bom.
Gestão de Energia
O design de energia mantém o dispositivo vivo, repetível e entediante, no melhor sentido da palavra. Abrange reguladores, carregamento, medição de combustível, comutação de carga e opções de proteção que devem lidar tanto com eventos de corrente de pico quanto com expectativas de modo de sono profundo.
A seleção de Buck/boost/LDO se beneficia da avaliação da eficiência em toda a faixa de carga, não apenas em um único ponto de operação. A corrente de quiescência em modo de sono frequentemente decide se um produto atende às expectativas da bateria.
Rádios podem criar picos de corrente agudos; capacitância de bulk, roteamento de baixa impedância e laços de controle estáveis tendem a decidir se o sistema permanece ativo durante os picos de transmissão. Muitos reinicializações misteriosas acabam voltando para quedas transitórias em vez de firmware, o que pode ser uma lição humilhante, mas útil durante a integração.
A vida útil da bateria geralmente é ganha durante o sono, onde pequenos vazamentos se acumulam em perdas mensuráveis.
• Configuração de sono profundo com apenas as fontes de ativação que são realmente utilizadas.
• RTC ou temporizadores de baixa potência para ativações periódicas.
• Interrupções GPIO ou de sensores para ativações baseadas em eventos.
• Gatilhos de energia para sensores e periféricos que não precisam de polarização contínua.
Medir o consumo de sono cedo em hardware real e, em seguida, tratar aumentos microampere inesperados como bugs tende a prevenir o lento desgaste onde muitos blocos "quase desligados" silenciosamente erodem o tempo de execução.
A escolha do IC de carregamento depende da química, limites térmicos, restrições regulamentares e do ambiente esperado. A seleção do medidor de combustível deve refletir as necessidades de precisão em relação à temperatura, carga e envelhecimento. Para implantações ao ar livre ou não aquecidas, o comportamento em baixa temperatura muitas vezes se torna o fator determinante da qualidade percebida, portanto, limites de tensão conservadores e relatorios de capacidade honestos reduzem as reclamações de desligamento abrupto.
Sobrecorrente, sobretensão, polaridade reversa e comportamento ESD devem ser tratados como condições operacionais normais para muitas implantações. Ambientes industriais comumente produzem eventos de descarga de cabos e transientes indutivos que podem parecer "azar" a menos que o design os antecipe. Clamps apropriados, fusíveis, diodos TVS, controle de corrente de partida e decisões de isolamento muitas vezes decidem se um dispositivo sobrevive ao seu primeiro mês com a reputação intacta.
Componentes de Armazenamento
O armazenamento contém firmware, configuração, certificados e registros. A escolha entre NOR/NAND flash, EEPROM, FRAM, eMMC ou microSD tende a ser determinada pela durabilidade, desempenho, custo do BOM e quão dolorosa seria uma gravação corrompida operacionalmente.
Dispositivos reais enfrentam quedas de tensão, reinicializações de watchdog e gravações parciais.
• Checksums ou CRCs para configuração e registros.
• Nivelamento de desgaste ou frequência de gravação limitada para mídia baseada em flash.
• Registros de journaling ou apenas adição para dados que não podem ser gravados pela metade.
Um padrão operacional frequente é o registro em buffer circular com taxas de gravação limitadas, o que limita o consumo silencioso de durabilidade enquanto ainda deixa migalhas suficientes para depurar problemas de campo.
Slots de firmware A/B mais lógica de inicialização verificada e de reversão fornecem uma rede de segurança prática durante atualizações interrompidas. Sem essas salvaguardas, uma única perda de energia durante uma atualização pode deixar dispositivos no campo em um estado sem saída. Produtos que escalam suavemente geralmente tratam a recuperabilidade no mesmo nível que os recursos de envio, pois os custos de suporte tendem a acompanhar a qualidade da história de recuperação.
Certificados e chaves devem ser armazenados com resistência a violação e controle de acesso em mente, não apenas em algum lugar não volátil. Mesmo com armazenamento seguro, planos para rotação de chaves, revogação e resposta a incidentes reduzem a exposição de longo prazo quando uma credencial vaza ou uma frota é parcialmente comprometida.
Componentes de Interface
LEDs, displays, botões, microfones, câmeras e sensores biométricos moldam a usabilidade, mas também consomem energia, risco de EMI e considerações de privacidade. Uma interface que parece consistente sob estresse muitas vezes reflete um design elétrico disciplinado mais do que o polimento da interface.
Botões tendem a precisar de desvio e proteção ESD para evitar leituras esporádicas incorretas.
Microfones e câmeras tendem a precisar de trilhas limpas e aterramento cuidadoso para evitar artefatos intermitentes que os usuários interpretam como "instáveis".
• Separação de caminhos analógicos sensíveis de comutação de alta corrente e caminhos RF.
• Planejamento do caminho de retorno para limitar acoplamento de ruído.
• Escolhas de blindagem e filtragem que correspondem à estratégia de invólucro e cabo.
Falhas intermitentes da interface são frequentemente causadas pelo acoplamento de rádios ou motores, e pode ser surpreendentemente satisfatório corrigi-las com disciplina de layout e aterramento em vez de intermináveis soluções alternativas de firmware.
Dispositivos se comportam de maneira mais previsível quando têm uma história offline que não depende da rede estar disponível.
Feedback local claro (estados de LED inequívocos e sinalização de erro mínima e precisa) tende a reduzir a carga de suporte e evita a frustração do usuário que vem de comportamentos de falha silenciosa.
Atuadores
Atuadores convertem a intenção de controle em movimento, calor ou força, e geralmente requerem circuitos de interface além de um pino direto do MCU. Como os atuadores interagem com o mundo físico, os modos de falha tendem a ser visíveis, custosos e emocionalmente escalatórios para os usuários. Motores, solenóides, válvulas e relés comumente precisam de estágios MOSFET, pontes H ou ICs de driver dedicados dimensionados para correntes e transientes reais.
• Diodos flyback ou snubbers para cargas indutivas.
• Detecção de corrente para detecção de parada e resposta a sobrecarga.
• Considerações de design térmico para cargas contínuas ou de alta demanda.
A experiência de campo frequentemente mostra problemas relacionados a atuadores como uma fonte frequente de falhas, e a subavaliação conservadora mais a detecção de falhas tende a melhorar o comportamento da frota de uma forma que as equipes de suporte notam rapidamente.
Um dispositivo deve permanecer seguro quando o firmware falha, a nuvem está inacessível ou os comandos chegam tarde.
• Watchdogs e estratégia de reinicialização alinhados com saídas seguras.
• Estados de saída padrão seguros definidos por atuador e por modo.
• Posições mecânicas de falha segura onde a aplicação exige.
Os designs mais resilientes tratam a perda de conectividade como um modo de operação normal e definem exatamente o que o atuador faz durante esse período, de modo que o comportamento permaneça previsível, mesmo quando tudo mais é imperfeito.
Integração em Nível de Sistema
Melhorias de alto impacto frequentemente vêm de práticas de integração que forçam todo o sistema a contar a verdade cedo.
• Validação de integridade de energia sob as piores cargas de rádio e atuador.
• Controle de ruído ao longo de sensores analógicos, reguladores de comutação e drivers de alta corrente.
• Fluxos de inicialização, atualização e recuperação com estados mensuráveis e clara observabilidade.
• Testes ambientais (temperatura, umidade, vibração) escolhidos para corresponder a condições reais de implantação.
Quando essas atividades são tratadas como trabalho de engenharia do dia a dia, em vez de cerimônias de estágio final, as escolhas de componentes geralmente se tornam menos dramáticas, e o comportamento do dispositivo tende a permanecer consistente do protótipo à implantação em massa.
Conclusão
Sistemas IoT bem-sucedidos dependem de um loop de dados completo e confiável que inclui sensoriamento, condicionamento de sinal, processamento, comunicação, segurança e gerenciamento de energia. Cada estágio afeta o desempenho geral, a vida útil da bateria, a precisão e a experiência do usuário. Ao equilibrar hardware, firmware, redes e restrições operacionais, os dispositivos IoT podem oferecer monitoramento, controle e automação confiáveis em uma ampla variedade de aplicações.
Perguntas Frequentes [FAQ]
1. Por que muitos projetos IoT falham devido à qualidade da medição em vez de problemas de conectividade?
A conectividade muitas vezes recebe a maior parte da atenção durante o desenvolvimento, porque painéis de controle e integrações em nuvem são altamente visíveis. No entanto, medições imprecisas causadas por má colocação do sensor, vibração, efeitos de fluxo de ar, acoplamento térmico, ruído ou erros de instalação podem comprometer todo o sistema. Se os dados originais forem pouco confiáveis, mesmo as análises, plataformas em nuvem e redes de comunicação mais avançadas não podem produzir decisões confiáveis. O sucesso a longo prazo do IoT geralmente começa com medições estáveis em vez de recursos de conectividade sofisticados.
2. Por que a montagem do sensor deve ser considerada parte do próprio sistema de sensoriamento?
Sensores medem condições físicas através de sua interação com o ambiente circundante. A força de montagem, o design da embalagem, o roteamento de cabos, o fluxo de ar, a transferência de vibrações e o contato térmico podem alterar o que o sensor percebe. Um sensor perfeitamente calibrado ainda pode produzir leituras enganosas se estiver montado de forma inadequada. Em muitas implantações, erros relacionados à instalação contribuem com mais incerteza nas medições do que as próprias especificações do sensor, tornando a integração mecânica uma parte crítica do desempenho geral do sensoriamento.
3. Por que a superamostragem é frequentemente uma ameaça oculta à vida útil da bateria em dispositivos IoT?
Amostragem de dados com mais frequência do que o necessário aumenta a carga de processamento, o uso de memória e a atividade de comunicação. Como a transmissão sem fio é frequentemente o maior consumidor de energia em produtos IoT alimentados por bateria, coletar dados excessivos pode aumentar indiretamente o uso do rádio e encurtar o tempo de operação. Embora altas taxas de amostragem possam parecer melhorar a precisão, frequentemente criam conjuntos de dados maiores sem fornecer melhorias significativas na qualidade da decisão. Estratégias de amostragem eficazes equilibram os requisitos de detecção de eventos com o consumo de energia e as necessidades de reportação.
4. Por que dispositivos IoT bem-sucedidos separam a lógica de medição da lógica de tomada de decisão?
Valores brutos de sensores naturalmente flutuam devido ao ruído, variação ambiental e comportamento normal do processo. Se cada medição acionar diretamente uma ação, os sistemas podem se tornar instáveis e gerar alarmes falsos. Ao separar a coleta de medições da lógica de decisão usando histerese, máquinas de estado, filtragem, janelas de temporização e regras de validação, os dispositivos podem permanecer responsivos enquanto evitam reações desnecessárias a flutuações temporárias. Essa abordagem melhora a confiabilidade e cria um comportamento de sistema mais previsível em condições do mundo real.
5. Por que muitas decisões críticas de IoT são processadas localmente em vez de serem delegadas à nuvem?
Sistemas em nuvem fornecem análises valiosas a longo prazo, gerenciamento de frotas e insights preditivos, mas atrasos e quedas na rede podem torná-los inadequados para funções de proteção sensíveis ao tempo. Eventos como condições de sobrecorrente, superaquecimento, paradas de motor ou desligamentos de segurança muitas vezes exigem ação imediata. Aguardar a confirmação da nuvem poderia permitir que danos ao equipamento ou condições inseguras se desenvolvessem. Por essa razão, decisões críticas de proteção e controle são comumente executadas na borda, enquanto plataformas em nuvem se concentram na monitorização e otimização.
Blog relacionado
-
Quantos zeros em um milhão, bilhões, trilhões?
![Quantos zeros em um milhão, bilhões, trilhões?]()
29/07/2024
Milhões representam 106, uma figura facilmente agressável quando comparada aos itens cotidianos ou salários anuais. Bilhão, equivalente a 109, com... -
Folha de dados, circuito, equivalente, pinagem
![Folha de dados, circuito, equivalente, pinagem]()
28/08/2024
O IRLZ44N é um MOSFET de potência n amplamente utilizado.Reconhecido por seus excelentes recursos de comutação, é altamente adequado para inúmer... -
Temperatura da bateria muito baixa, o carregamento parou.Como consertar isso?
![Temperatura da bateria muito baixa, o carregamento parou.Como consertar isso?]()
06/10/2024
Os problemas de carregamento da bateria do telefone celular são comuns, mas podem ser efetivamente gerenciados.A temperatura desempenha um grande pap... -
Guia abrangente do transistor BC547
![Guia abrangente do transistor BC547]()
04/07/2024
O transistor BC547 é comumente usado em uma variedade de aplicações eletrônicas, variando de amplificadores de sinal básicos a circuitos complexo... -
Um guia completo para os multiplexadores e seu papel nos sistemas digitais
![Um guia completo para os multiplexadores e seu papel nos sistemas digitais]()
20/09/2025
Os multiplexadores são componentes em sistemas digitais, projetados para canalizar vários sinais de entrada em uma única linha de saída usando ló... -
Guia abrangente do SCR (retificador controlado por silício)
![Guia abrangente do SCR (retificador controlado por silício)]()
22/04/2024
Retificadores controlados por silício (SCR), ou tiristores, desempenham um papel fundamental na tecnologia de eletrônicos de energia devido ao seu d... -
LR621, SR621SW, 364, equivalentes de bateria AG1 e substituições
![LR621, SR621SW, 364, equivalentes de bateria AG1 e substituições]()
15/07/2024
As baterias de botão LR621 e SR621SW são predominantes em dispositivos eletrônicos compactos, como relógios, pequenos brinquedos, calculadoras e c... -
Fundamentos de circuitos de amplificadores operacionais
![Fundamentos de circuitos de amplificadores operacionais]()
28/12/2023
No mundo intrincado da eletrônica, uma jornada para seus mistérios invariavelmente nos leva a um caleidoscópio de componentes do circuito, requinta... -
Comparando diferenças e aplicações de NMOs e PMOs
![Comparando diferenças e aplicações de NMOs e PMOs]()
15/11/2024
Compreender as diferenças entre os transistores de NMOs e PMOs é importante no projeto de circuitos eficientes.NMOs (NMOS (PMOs (PMOs (Metal-óxido-... -
CR2450 vs CR2032 Comparação: Tudo o que você precisa saber
![CR2450 vs CR2032 Comparação: Tudo o que você precisa saber]()
15/09/2025
As baterias de botão como CR2450 e CR2032 alimentam muitos eletrônicos diários, desde relógios e controles remotos a dispositivos médicos e indus...








Peças quentes
- MAX4052EEE+T
- TC58NVG0S3EBAI4
- CXD3622GA-T4
- HYB18TC256160BF-2.5
- 12105U750JAT9A
- GRM21BR71A475MA73L
- AD7829BR-REEL
- XC2VP40-6FFG1152C
- NRF51822-QFAB-R
- MAX3491E
- 08055C392KAT2A
- STV8357FSX
- CY7C1354CV25-200AXC
- GRM0336R1E430GD01D
- CAV24C16YE-GT3
- TAJA105M035RNJ
- AD734BNZ
- CS3002-ISZ
- MC74VHCT00ADTR2G
- YDA156-VZE2
- GJM0335C1ER50BB01D
- THS4211DRCR
- ADUM5402CRWZ
- MAX3262CAG-T
- GRM1885C2A2R0BA01D
- XPC850SRZT80BU
- LM2698MMX-ADJ
- APW7166KE-TRG
- 0805ZC473JAZ2A
- 7MBR15SA120B-50
- AD9510BCPZ
- S-22H12IF10
- LD031A270FAB2A
- S1D16702F00A100
- VI-J63-01
- HYB18T256800AF-5
- DCM3623T36G31C2T00
- T491B686M010AH
- 8314H
- BCM56324AOKFEBG
- LPC2917FBD144/01
- SM6781BV-E2
- TP1544A-TR
- TLV2442IPWR
- D1232AA-7A-E
- PS8811QFN36GTR2-A0
- BCM75639ZZKFEB03G
- TPS25865QRPQRQ1
- SDURD1060CT
- LTC7000JMSE#PBF