- Português
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
O que é um NPU e como funciona em dispositivos de IA?
Catálogo

O que é um NPU?
Uma Unidade de Processamento Neural (NPU) é um processador especializado projetado para lidar com tarefas de inteligência artificial com mais eficiência do que um processador de uso geral.Sua principal função é acelerar as operações de redes neurais usadas em recursos como reconhecimento de imagem, processamento de voz, detecção de objetos e inferência de IA em tempo real.Ao contrário de uma CPU, que é construída para gerenciar muitas tarefas de computação diferentes, uma NPU concentra-se em cálculos relacionados à IA.Ele é otimizado para processar grandes quantidades de dados ao mesmo tempo, tornando-o adequado para cargas de trabalho que exigem rápido reconhecimento de padrões e tomada de decisões.Em dispositivos modernos, as NPUs ajudam os recursos de IA a serem executados diretamente no hardware local, em vez de dependerem totalmente de servidores em nuvem.Isso permite que smartphones, câmeras inteligentes, robôs, veículos e dispositivos de ponta respondam mais rapidamente e usem menos energia.Por causa disso, as NPUs tornaram-se uma parte importante dos sistemas inteligentes modernos.
Arquitetura central e módulos de processamento de uma NPU
Uma NPU é construída a partir de vários módulos de hardware especializados que trabalham juntos para processar cargas de trabalho de rede neural de forma rápida e eficiente.Em vez de enviar todas as operações através de um processador de uso geral, a carga de trabalho é dividida em blocos de hardware dedicados que processam dados continuamente em paralelo.Essa estrutura melhora a velocidade de inferência de IA, reduz a movimentação desnecessária de dados, reduz o consumo de energia e ajuda a manter o uso eficiente da memória.
Durante o processamento de IA, os dados fluem através de vários estágios dentro do processador.Os dados de entrada entram primeiro no pipeline de computação, onde são executadas operações matemáticas em grande escala.Os resultados intermediários passam então pelo processamento de ativação, aceleração de tensor, operações relacionadas à imagem e hardware de otimização de memória antes que a saída final seja produzida.Como esses módulos operam juntos em uma sequência coordenada, a NPU pode manter um alto rendimento mesmo ao executar grandes modelos de redes neurais.
Módulos principais de computação e ativação
O principal mecanismo de computação dentro de uma NPU é a unidade Multiply-Accumulate (MAC).A maioria das cargas de trabalho de redes neurais executa repetidamente multiplicação e adição em conjuntos de dados muito grandes, de modo que esse hardware lida com a maior parte da computação de IA durante a inferência.Quando os dados de entrada entram em uma rede neural, os valores são multiplicados pelos valores de peso armazenados e depois somados para gerar novos resultados.Este processo se repete continuamente em muitas camadas da rede neural.
As NPUs modernas geralmente contêm centenas ou milhares de unidades MAC operando simultaneamente.Em vez de calcular uma operação por vez, o hardware distribui as cargas de trabalho por vários caminhos de execução paralelos.Grandes lotes de dados de IA passam juntos pelo processador, melhorando significativamente a velocidade de inferência e mantendo a latência baixa.Em sistemas de reconhecimento de imagem, por exemplo, as unidades MAC varrem repetidamente grupos de pixels e combinam valores de filtro para detectar bordas, texturas, formas e padrões.Nos modelos de linguagem, o mesmo hardware executa operações vetoriais e matriciais em grande escala para processar tokens e relacionamentos entre palavras.
Após a conclusão desses cálculos matemáticos, os resultados passam para o módulo Função de ativação.As redes neurais dependem de funções de ativação não linear para processar relacionamentos complexos dentro dos dados.Sem o processamento de ativação, a rede realizaria apenas cálculos lineares simples e não poderia lidar com tarefas avançadas de IA de forma eficaz.
Este módulo executa funções como ReLU, Sigmoid e Tanh diretamente no hardware.Os valores recebidos são rapidamente transformados de acordo com a regra de ativação selecionada.ReLU, por exemplo, remove valores negativos enquanto preserva saídas positivas, ajudando a rede a se concentrar em sinais de recursos mais fortes durante a inferência.Como o processamento de ativação ocorre repetidamente em todas as camadas da rede neural, o hardware de aceleração dedicado ajuda a reduzir atrasos e evita que as principais unidades de computação fiquem sobrecarregadas.
Módulos de processamento de dados espaciais e tensores
As NPUs também incluem hardware especializado para lidar com operações de tensor e processamento de dados espaciais.Quase todos os modelos modernos de IA dependem de tensores, que são estruturas de dados multidimensionais usadas para organizar informações em dimensões como largura, altura, canais, camadas de recursos e lotes.Grandes quantidades de dados tensores movem-se continuamente entre as camadas da rede neural durante a inferência.
A Unidade de Aceleração Tensor processa essas estruturas tensoras diretamente no hardware.Operações como multiplicação, remodelagem, transformação e acumulação de tensores são executadas muito mais rapidamente do que em processadores de uso geral.Essa aceleração dedicada torna-se especialmente importante em arquiteturas de transformadores, sistemas de visão computacional, grandes modelos de linguagem e aplicações de IA em tempo real que exigem rendimento muito alto.
Juntamente com o processamento de tensores, os NPUs também contêm módulos projetados para operações de dados espaciais e 2D comumente usadas em cargas de trabalho de imagem e vídeo.Os sistemas de visão computacional redimensionam, reorganizam, filtram e movem constantemente grandes quantidades de dados de pixel antes do início de uma análise mais profunda de IA.Lidar com essas tarefas separadamente melhora a eficiência e reduz a pressão no mecanismo de computação principal.
Durante o processamento da imagem, o hardware gerencia operações como redução da resolução, movimentação do mapa de características, cópia da imagem, redimensionamento, corte e transferência de dados espaciais.Por exemplo, o vídeo de alta resolução capturado por uma câmera pode primeiro ser redimensionado e reorganizado antes de entrar no pipeline da rede neural.Isso reduz a carga computacional enquanto preserva informações visuais importantes necessárias para detecção de objetos e análise de cena.
Módulos de otimização de memória e compactação de dados
Os modelos modernos de IA requerem grandes quantidades de memória para armazenar pesos, tensores e dados intermediários de redes neurais.A transferência constante dessas informações entre a memória e o hardware de computação aumenta o uso da largura de banda, a latência e o consumo de energia.Para reduzir essa sobrecarga, os NPUs incluem módulos dedicados de compactação e descompactação de dados.
Antes que os dados sejam armazenados na memória, padrões repetidos e valores de peso são compactados em formatos menores.Durante a execução, as informações compactadas são rapidamente restauradas e enviadas diretamente para o pipeline de computação.Isso reduz o tráfego de memória e permite que mais dados de IA permaneçam na memória local de alta velocidade, mais próxima do processador.
Métodos avançados de compactação geralmente podem reduzir o tamanho do modelo várias vezes, mantendo quase a mesma precisão de inferência.Isto se torna especialmente importante em smartphones, sistemas embarcados, câmeras inteligentes, eletrônicos vestíveis e outros dispositivos de IA de ponta, onde a capacidade de memória e a eficiência energética são limitadas.
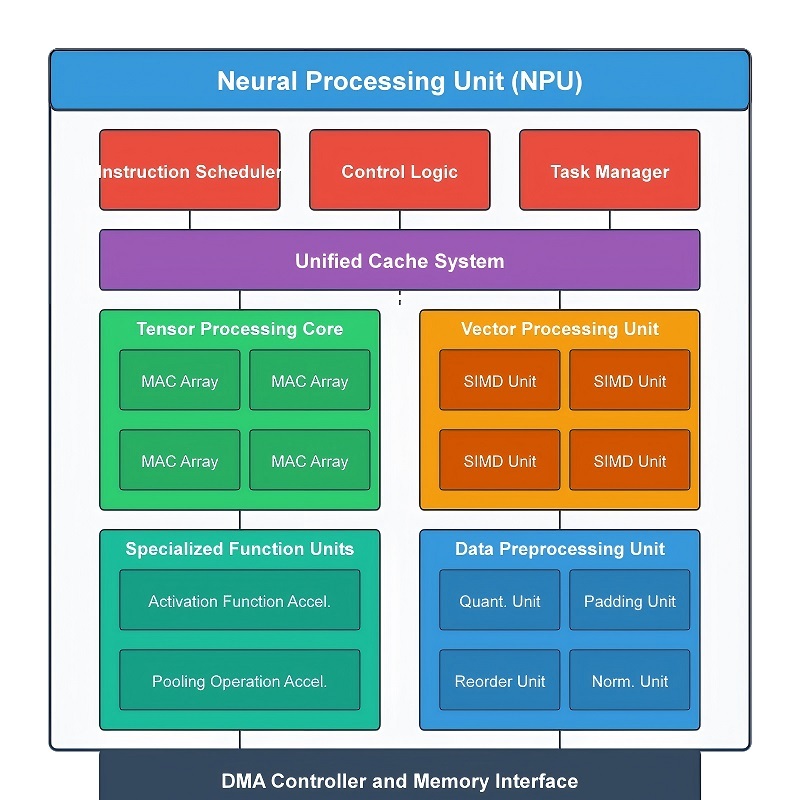
Como esses módulos funcionam juntos
O desempenho de uma NPU não depende de um único bloco de hardware.Sua eficiência vem de como todos os módulos de processamento operam juntos como um pipeline coordenado.
Uma carga de trabalho típica de IA começa com computação matemática em grande escala dentro das unidades MAC.Os resultados intermediários passam então pelo processamento de ativação para introduzir comportamento não linear na rede neural.O hardware de aceleração de tensor organiza e processa continuamente dados multidimensionais em todo o pipeline, enquanto os módulos de processamento espacial gerenciam operações relacionadas a imagens e vídeos.Ao mesmo tempo, o hardware de compactação reduz a sobrecarga de transferência de memória em segundo plano.
Como essas operações são executadas simultaneamente em caminhos de hardware dedicados, a NPU pode processar grandes cargas de trabalho de IA com alto rendimento, menor latência e eficiência energética muito melhor do que os processadores tradicionais.
NPUs em smartphones e IA móvel
Os smartphones modernos realizam um grande número de operações a cada segundo.Um telefone pode ser desbloqueado com reconhecimento facial, abrir a câmera, processar fotos, traduzir fala e executar aplicativos assistidos por IA quase instantaneamente.Para suportar este nível de desempenho em dispositivos móveis finos com capacidade de bateria limitada, os smartphones contam com arquiteturas System-on-Chip (SoC) altamente integradas.
Dentro do SoC, vários processadores trabalham juntos e cada processador é otimizado para uma carga de trabalho diferente.A CPU gerencia o controle do sistema, aplicativos e tarefas gerais de computação.A GPU lida com renderização gráfica, jogos e processamento visual.A NPU (Unidade de Processamento Neural) concentra-se especificamente na computação de IA.
Em vez de rotear cargas de trabalho de rede neural por meio da CPU ou GPU, os smartphones direcionam muitas tarefas de IA para a NPU, onde o hardware é otimizado para processamento rápido de IA paralelo.Essa separação melhora a eficiência porque cada processador lida com o tipo de carga de trabalho para o qual foi projetado.Como resultado, os smartphones podem realizar operações avançadas de IA com tempos de resposta mais rápidos, menor latência e melhor eficiência energética.
Como os NPUs mudaram a IA dos smartphones
Antes de as NPUs móveis se tornarem comuns, muitos recursos de IA de smartphones dependiam fortemente da computação em nuvem.Tarefas como reconhecimento de voz, tradução de idiomas, aprimoramento de imagens e assistentes inteligentes muitas vezes exigiam que os dados fossem carregados em servidores remotos para processamento antes que os resultados fossem retornados ao dispositivo.Isto criou atrasos, aumentou o tráfego de rede e levantou preocupações com a privacidade.
A introdução de NPUs móveis dedicadas alterou significativamente esse fluxo de trabalho.Os modelos de IA agora podem ser executados diretamente no próprio smartphone, permitindo que muitas operações sejam executadas localmente em tempo real, em vez de depender inteiramente de servidores externos.
Essa mudança proporcionou várias vantagens importantes:
• Menor latência porque os dados não precisam mais de comunicação constante na nuvem
• Tempos de resposta de IA mais rápidos durante operações em tempo real
• Melhor proteção de privacidade, já que dados confidenciais podem permanecer no dispositivo
• Menor consumo de energia por meio de hardware otimizado especificamente para cargas de trabalho de IA
• Desempenho de IA mais estável, mesmo com conexões de Internet fracas ou indisponíveis
À medida que as NPUs móveis se tornaram mais poderosas, os smartphones começaram a executar recursos avançados de IA continuamente em segundo plano, sem atrasos perceptíveis durante o uso diário.
Como os smartphones usam NPUs em operações reais
Fotografia AI e processamento de imagens
Um dos usos mais visíveis de NPUs móveis é a fotografia de IA.As câmeras dos smartphones modernos não dependem mais apenas de sensores de imagem e algoritmos tradicionais de processamento de imagem.Os modelos de IA agora analisam dados de imagem continuamente enquanto a câmera está operando.
Quando o aplicativo da câmera é aberto, o smartphone começa imediatamente a processar o fluxo de imagem recebido, quadro a quadro.O NPU analisa condições de iluminação, limites de objetos, detalhes faciais, cores, texturas e padrões de movimento em tempo real.Com base nesta análise, o sistema ajusta a exposição, o equilíbrio de branco, as configurações de HDR, a nitidez e o contraste quase instantaneamente antes de a imagem ser capturada.
Em fotografia com pouca luz, o NPU combina vários quadros de imagem para melhorar o brilho e reduzir o ruído visual.Durante a fotografia de retrato, o processador separa os assuntos em primeiro plano das áreas de fundo e aplica efeitos de profundidade com mais precisão nas bordas, como cabelos, óculos e contornos de roupas.
O reconhecimento de cena também depende muito do NPU.O processador compara padrões de imagem com modelos de IA treinados para identificar ambientes como alimentos, paisagens, animais de estimação, documentos, pôr do sol ou cenas noturnas.Uma vez reconhecida, a câmera ajusta automaticamente as configurações para otimizar a qualidade da imagem.
Como esses cálculos ocorrem diretamente no smartphone, a fotografia de IA parece quase instantânea, mesmo que grandes quantidades de computação em rede neural ocorram continuamente em segundo plano.
Reconhecimento de voz e assistentes de IA
Assistentes de voz e recursos relacionados à fala também dependem fortemente da aceleração local de IA.Quando um usuário fala com o smartphone, o microfone captura sinais de áudio brutos que devem ser limpos, separados e convertidos em padrões de fala reconhecíveis.
A NPU processa continuamente o fluxo de áudio identificando fonemas, filtrando ruídos de fundo e combinando padrões sonoros com modelos de reconhecimento de fala.O processamento local de IA permite que palavras de ativação e comandos de voz comuns sejam detectados quase instantaneamente, sem transmitir constantemente gravações de áudio para servidores em nuvem.
Isso melhora a capacidade de resposta para tarefas como:
• Comandos de voz
• Transcrição de fala em tempo real
• Tradução de idiomas
• Interação com assistente de IA
• Aprimoramento de chamadas de IA
• Supressão de ruído durante videochamadas
Como grande parte do processamento ocorre diretamente no dispositivo, a interação por voz permanece mais suave mesmo em condições de rede instáveis.
Jogos de IA e otimização do sistema em tempo real
Os smartphones modernos também usam NPUs para otimização de jogos e gerenciamento inteligente de sistemas.Durante o jogo, os modelos de IA monitoram a demanda de renderização de quadros, o comportamento da carga de trabalho, as condições térmicas, os padrões de entrada de toque e o uso da bateria em tempo real.
O sistema pode ajustar dinamicamente as cargas de trabalho da GPU, otimizar a alocação de energia, estabilizar as taxas de quadros e reduzir o superaquecimento durante longas sessões de jogo.Alguns smartphones também usam técnicas de upscaling de IA e previsão de movimento para melhorar a suavidade visual e, ao mesmo tempo, manter menor consumo de energia.
Fora dos jogos, o NPU ajuda a otimizar aplicativos em segundo plano, gerenciamento de bateria, interações preditivas do usuário e agendamento de tarefas com base nos padrões de uso do dispositivo.
Evolução dos NPUs Móveis
O desenvolvimento de NPUs móveis acelerou rapidamente à medida que as cargas de trabalho de IA de smartphones se tornaram mais avançadas e exigentes em termos computacionais.
|
Período |
Desenvolvimento de NPU Móvel |
|
2017 – Primeiros NPUs móveis comerciais |
Huawei apresentou um dos primeiros smartphones comerciais
NPUs através do processador Kirin 970.Isto marcou uma grande mudança em direção
aceleração de IA em grande escala no dispositivo dentro de smartphones de consumo.Em vez de
contando principalmente com CPUs e GPUs para tarefas de IA, smartphones agora incluídos
hardware de IA dedicado diretamente dentro da arquitetura SoC. |
|
2018 – Expansão da IA no dispositivo |
A Apple apresentou o Neural Engine dentro do A12 Bionic
chip, melhorando o processamento de IA para reconhecimento facial, computacional
fotografia e recursos móveis inteligentes.A IA no dispositivo tornou-se um importante
foco no desenvolvimento de smartphones emblemáticos. |
|
2019–2020 — Integração de IA em todo o setor |
Os principais fabricantes de chips, incluindo Qualcomm, Samsung e
A MediaTek começou a integrar aceleradores de IA dedicados em dispositivos móveis emblemáticos
processadores.O desempenho da IA começou a se tornar um importante fator competitivo em
projeto de hardware de smartphones. |
|
2021–2023 – O processamento de IA se torna uma referência central |
Os fabricantes de smartphones compararam cada vez mais o NPU
desempenho junto com o desempenho da CPU e GPU.As NPUs tornaram-se centrais para
fotografia computacional, IA de voz, aprimoramento de vídeo, otimização de bateria,
e recursos de sistema inteligentes. |
|
2024–2025 — Grandes modelos de IA rodando em smartphones |
As NPUs móveis modernas ganharam poder de processamento suficiente para
oferecer suporte a modelos maiores de IA diretamente em smartphones e dispositivos de ponta.Mais IA
as cargas de trabalho agora podem ser executadas localmente sem depender muito da nuvem
infra-estrutura, melhorando a capacidade de resposta e a privacidade. |
Comparação dos atuais NPUs móveis convencionais
Os principais processadores de smartphones modernos agora incluem arquiteturas NPU altamente avançadas, otimizadas para inferência de IA em tempo real, alto rendimento e maior eficiência energética.
|
Processador móvel |
Recursos de NPU |
|
Apple A17 Pro |
Inclui um mecanismo neural de 26 núcleos projetado para
processamento de IA no dispositivo.A arquitetura melhora a fotografia AI, voz
reconhecimento e recursos de sistema inteligente em tempo real em dispositivos Apple. |
|
Qualcomm Snapdragon 8 geração 3 |
Usa um processador Hexagon AI atualizado e otimizado para
IA generativa, aceleração de rede neural, processamento avançado de imagens e
cargas de trabalho de IA móveis eficientes. |
|
Dimensão MediaTek 9300 |
Inclui uma APU (unidade de processamento de IA) de sexta geração com
grandes melhorias na velocidade de inferência de IA e processamento de IA em tempo real
capacidade para smartphones e dispositivos de ponta. |
|
Samsung Exynos2400 |
Apresenta um NPU móvel de última geração focado em maior rapidez
processamento de IA no dispositivo para fotografia computacional, sistema inteligente
operações e aplicativos móveis avançados de IA. |
NPU vs GPU vs CPU: Principais diferenças no processamento de IA
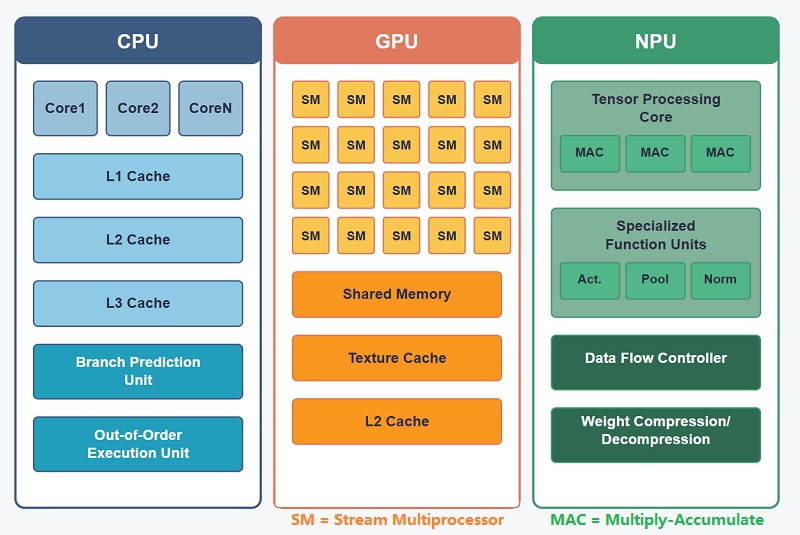
Tanto as GPUs quanto as NPUs são projetadas para processar grandes quantidades de dados em paralelo, mas foram construídas para finalidades muito diferentes.Uma GPU foi originalmente desenvolvida para renderização gráfica, enquanto uma NPU foi criada especificamente para computação de redes neurais e inferência de IA. Devido a essa diferença nos objetivos de design, os dois processadores lidam com cargas de trabalho de IA de maneiras muito diferentes.As GPUs podem executar modelos de IA de forma eficaz, especialmente em sistemas de treinamento em larga escala, mas ainda carregam grande parte da complexidade de um processador gráfico.As NPUs simplificam muitas dessas operações, concentrando-se quase inteiramente na computação relacionada à IA.
|
Recurso |
CPU
(Unidade Central de Processamento) |
GPU
(Unidade de Processamento Gráfico) |
NPU
(Unidade de Processamento Neural) |
|
Objetivo principal |
Uso geral
computação e controle de sistema |
Paralelo
gráficos e computação de alto desempenho |
Inferência de IA e
aceleração de rede neural |
|
Carga de Trabalho Primária |
Operando
sistemas, aplicativos, multitarefa |
Gráficos
renderização, treinamento em IA, computação científica |
Processamento de IA,
operações de tensor, inferência de aprendizagem profunda |
|
Estilo de processamento |
Sequencial
processamento |
Paralelo maciço
processamento |
Otimizado para IA
processamento paralelo |
|
Projeto Central |
Poucos poderosos e
núcleos flexíveis |
Milhares de
núcleos de execução paralela |
IA especializada
unidades de aceleração |
|
Desempenho de IA |
Moderado |
Alto |
Muito alto para IA
inferência |
|
Matriz
Velocidade de multiplicação |
Limitado |
Rápido |
Altamente otimizado |
|
Tensor
Processamento |
Baseado em software |
Suportado
através da aceleração da GPU |
Tensor dedicado
hardware de aceleração |
|
Eficiência energética |
Menor para IA
cargas de trabalho |
Moderado a alto
consumo de energia |
Altamente poderoso
eficiente |
|
Geração de Calor |
Moderado |
Alto sob pesado
cargas de trabalho |
Menor durante IA
inferência |
|
Largura de banda de memória
Uso |
Moderado |
Muito alto |
Otimizado e
reduzido |
|
Latência em IA
Tarefas |
Superior |
Moderado |
Muito baixo |
|
IA em tempo real
Capacidade |
Limitado |
Bom |
Excelente |
|
Melhor para IA
Treinamento |
Não é o ideal |
Excelente |
Limitado em comparação
para GPUs |
|
Melhor para IA
Inferência |
Cargas de trabalho básicas |
Alto desempenho
inferência |
Otimizado
inferência em tempo real |
|
Comum
Aplicativos |
PCs, servidores,
sistemas operacionais |
Jogos, IA
treinamento, renderização, simulações |
Smartphones,
IA de ponta, robótica, câmeras inteligentes |
|
Dependência de
IA na nuvem |
Superior |
Moderado |
Menor devido a
aceleração local de IA |
|
Bateria
Eficiência em dispositivos móveis |
Inferior |
Moderado |
Alto |
|
Dispositivos Típicos |
Computadores,
laptops, servidores |
PCs para jogos, IA
servidores, estações de trabalho |
Smartphones, IoT
dispositivos, hardware de IA de ponta |
|
Custo e
Complexidade |
Uso geral
arquitetura |
Complexo
arquitetura de alto desempenho |
Especializado
Arquitetura focada em IA |
|
Principal vantagem |
Flexibilidade e
gerenciamento de sistema |
Grande escala
computação paralela |
Rápido e
processamento local eficiente de IA |
Unidades de Processamento Especializadas em Computação Moderna
Além da NPU, os sistemas de computação modernos usam muitos tipos diferentes de processadores porque nenhuma arquitetura única pode lidar com eficiência com todas as cargas de trabalho.Alguns processadores concentram-se no controle do sistema, alguns são especializados em renderização gráfica, enquanto outros são otimizados para aceleração de IA, rede, computação científica ou controle incorporado.
Dentro de smartphones, servidores, sistemas industriais, plataformas robóticas, veículos e dispositivos de IA de ponta modernos, várias unidades de processamento geralmente trabalham juntas simultaneamente.Cada processador lida com o tipo de carga de trabalho para o qual foi projetado especificamente, melhorando o desempenho, a eficiência energética e a capacidade de resposta em tempo real em ambientes de computação modernos.
CPU: Unidade Central de Processamento
Uma CPU (Unidade Central de Processamento) é o principal controlador da maioria dos sistemas de computação.Ele gerencia sistemas operacionais, aplicativos, coordenação de memória, agendamento de tarefas e comunicação entre componentes de hardware.
As CPUs são altamente flexíveis e podem lidar com muitas cargas de trabalho diferentes de maneira confiável, o que as torna essenciais em computadores, smartphones, servidores e sistemas embarcados.No entanto, eles são menos eficientes para cargas de trabalho paralelas de IA em grande escala em comparação com processadores mais especializados.
GPU: Unidade de Processamento Gráfico
Uma GPU (Unidade de Processamento Gráfico) é otimizada para processamento paralelo em grande escala.A arquitetura contém muitos núcleos de execução capazes de lidar com milhares de operações simultaneamente.
As GPUs foram originalmente desenvolvidas para renderização gráfica, mas agora são amplamente utilizadas para treinamento de IA, simulação científica, processamento de vídeo e computação de alto desempenho devido à sua forte capacidade de computação paralela.
TPU: Unidade de Processamento de Tensor
Uma TPU (Tensor Processing Unit) é otimizada para cargas de trabalho de IA baseadas em tensor e aceleração de aprendizado profundo em grande escala.Esses processadores são projetados principalmente para infraestrutura de IA em nuvem e ambientes de aprendizado de máquina de data center.
TPUs são altamente eficazes para:
• Treinamento de aprendizagem profunda
• Grandes modelos de IA
• Cálculo de tensores
• Serviços de IA em nuvem
• Aceleração de IA de alto rendimento
FPGA: Processamento de Hardware Reconfigurável
Um FPGA (Field-Programmable Gate Array) usa blocos lógicos programáveis que podem ser configurados para tarefas específicas após a fabricação.Ao contrário das arquiteturas de processador fixo, os FPGAs permitem que a própria função do hardware seja personalizada.
FPGAs são amplamente utilizados em:
• Sistemas de comunicação
• Eletrônica automotiva
• Automação industrial
• Sistemas aeroespaciais
• Computação de borda
• Dispositivos médicos
DPU: Unidade de Processamento de Dados
Uma DPU (unidade de processamento de dados) é otimizada para cargas de trabalho centradas em dados dentro de infraestrutura em nuvem e sistemas de rede.As DPUs ajudam a reduzir a carga de trabalho da CPU, acelerando a movimentação de dados, as operações de armazenamento, a criptografia e o gerenciamento do tráfego de rede.
Esses processadores são comumente usados em:
• Centros de dados
• Computação em nuvem
• Rede de alta velocidade
• Aceleração de armazenamento
• Infraestrutura de servidores
VPU: Unidade de processamento de visão
Uma VPU (Unidade de Processamento de Visão) é especializada em visão computacional e processamento de IA baseado em imagens.As VPUs aceleram cargas de trabalho como reconhecimento facial, detecção de objetos, rastreamento de movimento e análise de vídeo.
VPUs são comumente encontradas em:
• Câmeras inteligentes
• Sistemas de vigilância
• Robótica
• Veículos autônomos
• Sistemas AR/VR
• Dispositivos de visão Edge AI
UIP: Unidade de Processamento de Inteligência
Uma IPU (Unidade de Processamento de Inteligência) é projetada para cargas de trabalho de IA e aprendizado de máquina altamente paralelas.A arquitetura se concentra em melhorar a eficiência do fluxo de dados durante a execução de redes neurais em larga escala.
As IPUs são usadas para:
• Aceleração do aprendizado de máquina
• Reconhecimento de padrões
• Inferência de IA
• Processamento de tensor paralelo
• Pesquisa avançada de IA
BPU: Unidade de Processamento Cerebral
Uma BPU (Unidade de Processamento Cerebral) é otimizada para sistemas integrados de IA e inteligência de ponta.Esses processadores concentram-se na rápida inferência local de IA com menor consumo de energia.
BPUs são comumente usados em:
• Sistemas de detecção inteligentes
• Robótica
• Hardware de IA de ponta
• Sistemas de detecção de movimento
• Plataformas autônomas
HPU: Unidade de Processamento Holográfico
Uma HPU (Unidade de Processamento Holográfico) é projetada para computação holográfica, realidade mista e sistemas de análise espacial.
Processo de ajuda das HPUs:
• Mapeamento ambiental
• Rastreamento de movimento
• Fusão de sensores
• Interação espacial em tempo real
• Ambientes AR/VR
MPU e MCU: Processamento de Controle Incorporado
MPUs (unidades de microprocessador) e MCUs (unidades de microcontrolador) são amplamente utilizados em sistemas embarcados e eletrônicos de baixa potência.
MPUs são comumente usados em sistemas de computação embarcados que exigem controle em nível de sistema operacional, enquanto MCUs integram núcleos de processador, memória e controle de entrada/saída em um chip compacto para tarefas dedicadas de baixo consumo de energia.
Esses processadores são comumente encontrados em:
• Dispositivos IoT
• Controladores industriais
• Eletrônica automotiva
• Eletrodomésticos
• Sistemas embarcados portáteis
APU: Unidade de Processamento Acelerado
Uma APU (Unidade de Processamento Acelerado) combina funcionalidades de CPU e GPU dentro de um único pacote de processador.Essa integração melhora a eficiência energética, reduz o tamanho do hardware e permite que cargas de trabalho de computação e gráficos compartilhem recursos do sistema com mais eficiência.
APUs são comumente usadas em:
• Portáteis
• Minicomputadores
• Sistemas de jogos básicos
• Dispositivos multimídia
• Plataformas de computação portáteis
Por que os sistemas modernos usam vários processadores especializados
Os sistemas de computação modernos raramente dependem de uma arquitetura de processador único.Em vez disso, os dispositivos combinam vários processadores especializados porque diferentes cargas de trabalho exigem diferentes métodos de processamento.
Por exemplo, um sistema moderno pode usar:
• CPUs para controle do sistema
• GPUs para gráficos e computação paralela
• NPUs para inferência de IA
• VPUs para visão computacional
• DPUs para rede e movimentação de dados
• MCUs para tarefas de controle incorporadas
Ao distribuir cargas de trabalho em hardware dedicado, os sistemas modernos alcançam melhor desempenho, menor latência, maior eficiência energética e processamento mais eficaz em tempo real em ambientes de IA, gráficos, redes e computação incorporada.
Conclusão
As NPUs estão se tornando essenciais na computação moderna porque permitem que as tarefas de IA sejam executadas localmente, de forma rápida e eficiente, sem depender muito do processamento na nuvem.Sua arquitetura otimizada reduz a latência, o uso de energia, o movimento da memória e a geração de calor, tornando-os valiosos em smartphones, robótica, dispositivos de saúde, automação industrial, casas inteligentes, sistemas autônomos e plataformas de IA de ponta.À medida que os modelos de IA se tornam maiores e mais complexos, as futuras NPUs continuarão a melhorar através de arquiteturas mais inteligentes, computação de baixa precisão, processamento na memória, suporte local a grandes modelos, design avançado de semicondutores e recursos de segurança de IA mais fortes.
Perguntas frequentes [FAQ]
1. Por que as NPUs são mais eficientes que as CPUs para cargas de trabalho de redes neurais?
As NPUs são mais eficientes porque seu hardware é projetado especificamente para computação de IA, em vez de processamento de uso geral.Uma CPU lida com muitas tarefas de sistema diferentes sequencialmente, enquanto uma NPU se concentra principalmente em operações de tensores, multiplicação de matrizes, convolução e processamento de redes neurais paralelas.Isso permite que as NPUs concluam a inferência de IA mais rapidamente, usando menos energia e gerando menos calor.
2. Como o processamento paralelo melhora o desempenho da NPU durante a inferência de IA?
As NPUs dividem as cargas de trabalho de IA em muitas operações menores que são executadas simultaneamente em várias unidades de computação.Em vez de esperar que uma instrução termine antes de iniciar outra, grandes quantidades de dados da rede neural passam pelo processador em paralelo.Isso melhora significativamente o rendimento e reduz a latência durante cargas de trabalho, como reconhecimento de imagem, processamento de fala e detecção de objetos em tempo real.
3. Por que a computação de baixa precisão é importante nas NPUs modernas?
Muitos modelos de IA não requerem precisão numérica extremamente alta para produzir resultados precisos.As NPUs usam formatos como INT8 e FP16 para reduzir o uso de memória e a sobrecarga computacional.O processamento de menor precisão permite que mais operações sejam concluídas em menos tempo, melhorando a eficiência energética e mantendo um forte desempenho de inferência de IA.
4. Como as NPUs reduzem os gargalos de transferência de memória em comparação com as GPUs?
As NPUs colocam a memória e o hardware de computação mais próximos dentro da arquitetura do processador.Em vez de transferir repetidamente grandes quantidades de dados tensores entre a memória externa e os núcleos de processamento, muitas operações intermediárias permanecem próximas às unidades de execução.Isso encurta os caminhos de dados, reduz o uso de largura de banda, diminui a latência e melhora a eficiência energética geral.
5. Por que as NPUs estão se tornando úteis em smartphones e dispositivos de IA de ponta?
Os dispositivos modernos exigem processamento local rápido de IA com baixo consumo de energia e latência mínima.As NPUs permitem que smartphones e sistemas de ponta executem tarefas de IA, como reconhecimento facial, fotografia de IA, interação de voz e detecção de objetos diretamente no dispositivo, sem depender muito de servidores em nuvem.Isso melhora a capacidade de resposta, a privacidade e a eficiência da bateria.
6. Como as unidades MAC contribuem para a aceleração da NPU?
Unidades Multiply-Accumulate (MAC) lidam com operações repetidas de multiplicação e adição usadas em redes neurais.As NPUs modernas contêm centenas ou milhares de unidades MAC trabalhando simultaneamente, permitindo que grandes cargas de trabalho de IA sejam processadas com muito mais rapidez do que em processadores sequenciais tradicionais.
7. Por que os sistemas modernos de IA usam GPUs e NPUs em vez de depender de um tipo de processador?
GPUs e NPUs são otimizados para diferentes cargas de trabalho.As GPUs se destacam no treinamento de IA em grande escala, renderização de gráficos e computação paralela de alto desempenho, enquanto as NPUs são otimizadas para inferência de IA de baixo consumo de energia e processamento local em tempo real.Usar os dois processadores juntos permite que os sistemas equilibrem flexibilidade, desempenho e eficiência energética.
8. Como as NPUs melhoram o processamento de IA em tempo real em robótica e sistemas autônomos?
A robótica e os sistemas autônomos processam continuamente entradas de câmeras, mapeamento ambiental, dados de sensores e análise de movimento.As NPUs aceleram essas cargas de trabalho localmente com baixa latência, permitindo que os sistemas reajam rapidamente durante a navegação, detecção de obstáculos, reconhecimento de pedestres e tomada de decisões em tempo real.
9. Por que a IA no dispositivo está se tornando mais importante para o desenvolvimento futuro de NPU?
A IA no dispositivo reduz a dependência da computação em nuvem, permitindo que modelos de IA sejam executados diretamente no hardware local.Isso melhora a privacidade, reduz o uso da largura de banda da rede e permite respostas mais rápidas em tempo real.Espera-se que as futuras NPUs suportem modelos locais maiores de IA, processamento multimodal de IA e cargas de trabalho avançadas de IA generativa diretamente em dispositivos industriais e de consumo.
10. Como as futuras arquiteturas NPU poderiam mudar a eficiência do hardware de IA?
As futuras NPUs provavelmente usarão alocação de carga de trabalho mais inteligente, computação esparsa, processamento na memória, arquiteturas de chips e controle de precisão adaptativo para melhorar a eficiência.Estas tecnologias visam reduzir a computação desnecessária, diminuir o consumo de energia e aumentar o rendimento, ao mesmo tempo que suportam modelos de IA maiores e mais avançados em dispositivos de ponta, robótica, sistemas industriais e produtos eletrónicos de consumo inteligentes.
Blog relacionado
-
Quantos zeros em um milhão, bilhões, trilhões?
![Quantos zeros em um milhão, bilhões, trilhões?]()
29/07/2024
Milhões representam 106, uma figura facilmente agressável quando comparada aos itens cotidianos ou salários anuais. Bilhão, equivalente a 109, com... -
Folha de dados, circuito, equivalente, pinagem
![Folha de dados, circuito, equivalente, pinagem]()
28/08/2024
O IRLZ44N é um MOSFET de potência n amplamente utilizado.Reconhecido por seus excelentes recursos de comutação, é altamente adequado para inúmer... -
Temperatura da bateria muito baixa, o carregamento parou.Como consertar isso?
![Temperatura da bateria muito baixa, o carregamento parou.Como consertar isso?]()
06/10/2024
Os problemas de carregamento da bateria do telefone celular são comuns, mas podem ser efetivamente gerenciados.A temperatura desempenha um grande pap... -
Guia abrangente do transistor BC547
![Guia abrangente do transistor BC547]()
04/07/2024
O transistor BC547 é comumente usado em uma variedade de aplicações eletrônicas, variando de amplificadores de sinal básicos a circuitos complexo... -
Guia abrangente do SCR (retificador controlado por silício)
![Guia abrangente do SCR (retificador controlado por silício)]()
22/04/2024
Retificadores controlados por silício (SCR), ou tiristores, desempenham um papel fundamental na tecnologia de eletrônicos de energia devido ao seu d... -
LR621, SR621SW, 364, equivalentes de bateria AG1 e substituições
![LR621, SR621SW, 364, equivalentes de bateria AG1 e substituições]()
15/07/2024
As baterias de botão LR621 e SR621SW são predominantes em dispositivos eletrônicos compactos, como relógios, pequenos brinquedos, calculadoras e c... -
Fundamentos de circuitos de amplificadores operacionais
![Fundamentos de circuitos de amplificadores operacionais]()
28/12/2023
No mundo intrincado da eletrônica, uma jornada para seus mistérios invariavelmente nos leva a um caleidoscópio de componentes do circuito, requinta... -
Comparando diferenças e aplicações de NMOs e PMOs
![Comparando diferenças e aplicações de NMOs e PMOs]()
15/11/2024
Compreender as diferenças entre os transistores de NMOs e PMOs é importante no projeto de circuitos eficientes.NMOs (NMOS (PMOs (PMOs (Metal-óxido-... -
Um guia completo para os multiplexadores e seu papel nos sistemas digitais
![Um guia completo para os multiplexadores e seu papel nos sistemas digitais]()
20/09/2025
Os multiplexadores são componentes em sistemas digitais, projetados para canalizar vários sinais de entrada em uma única linha de saída usando ló... -
O que STD, AGM e gel significam em um carregador de bateria
![O que STD, AGM e gel significam em um carregador de bateria]()
10/07/2024
Os carregadores tradicionais de bateria de chumbo-ácido são conhecidos por sua simplicidade e confiabilidade.Eles cumprem seu objetivo efetivamente ...








Peças quentes
- SC6616STR
- 12065C683KAZ2A
- GRM0225C1ER30BDAEL
- K4D263238E-GC36
- LM3S6730-IQC50-A2
- EL5397ACS
- LD031C152KAB2A
- M50FW080N1
- ADP3338AKC-3.3-RL
- C0603C0G1E390J030BA
- 1812YC106KAT2A
- LE79231QCB
- SAB-C163-16F-25F
- 08051A1R0DAT2A
- 08052U200FAT2A
- S23306W519
- M24128-BWMN6P
- MM912F634CV2AP
- LE89116QVCT
- GCM0335C1E6R0DD03D
- LA73030-TLM-E
- ADM6996MX-AD-T-1
- GRM1555C1H6R6DZ01D
- LTC2435-1CGN#TRPBF
- PS421TQFP100G-A2
- LTC3853EUJ#TRPBF
- PIC18F8720-I/PT
- AOZ1267QI-01
- TLV2474AQDRQ1
- LM258DGKR
- CY7C1021CV33-15ZXI
- UCC5640PW-28
- PCI4512ZHK
- AD9238BSTRL-20
- MB603470PF-G-BNDE1-TK2
- TAJC686K010ANJ
- BCM5239UA3KQM
- BCM5787MKMLG
- TAZB684K025CRSZ0800
- T491C106K016ATAU007280
- VI-J0Y-CZ
- T491B226M016ATAU02
- ADAV41YZ/42YZKSTZ
- AS44CC373CAEF
- BCM3510KPF
- GS9091B
- S1D13778B00B100
- LNTK103F4-020-20
- THGBT2G6D1JBA01
- TLP293-4GB-TP.E